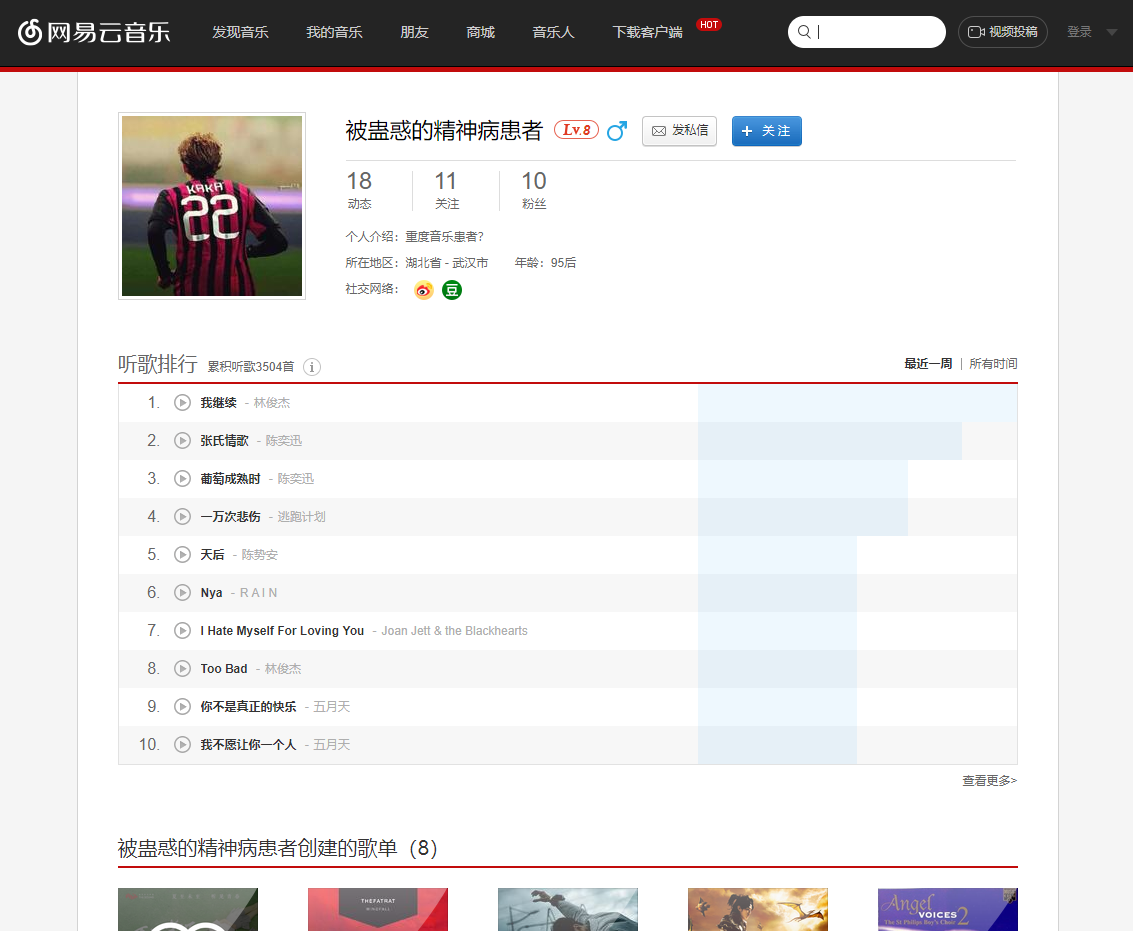
网易云音乐听歌排行
一些杂碎
决定学爬虫一部分的原因是对于网易云的评论让我产生了这个想法。说实话,网易云音乐这款产品做的很不错。不光是移动端还是PC端都有较好的用户体验,而且在刚刚踏入评论板块的时候,也的确被很多评论所感动,所以想汇集声音,这大概就是初衷吧。
还有一点就是网易云的确也是进阶爬取练手最好的项目了,无它。
功能
- 爬取用户所有时间的听歌排行
- 用户之间的数据匹配
分析
首先要分析网易云为什么说是一个进阶的练手项目,我下载了一个插件”Toggle JavaScript”。
在上一篇文章说的三个小Dome都是基于静态网页的爬取,但是现在很多网页都不是纯静态了很多数据都是异步加载的,这造成了很多数据用基本的requests是很难爬取到我们想要的信息的(想要的信息大部分也在动态加载里),所以单纯为了解决问题在来分析一下。
网易云音乐的个人首页是http://music.163.com/#/user/home?id=99962953,我们得到的是上图,能够看到最近一周的听歌排行,也可以观看所有时间,点击之后页面变成所有时间,但是页面地址没有变化,但是数据变化了。所以由此可以确定此网站不是静态,而是动态加载的。前面提到的插件”Toggle JavaScript”也可以观察,当选择要爬取某个网站的时候,点击该插件,它会吧所有是动态加载的数据屏蔽掉,那么就可以知道我需要的数据是不是需要处理。
很多资料都在说动态加载可以直接爬取关键的数据,直接获取Json。看看网易云行不行:chrome的检查->Network->XHR
最近一周: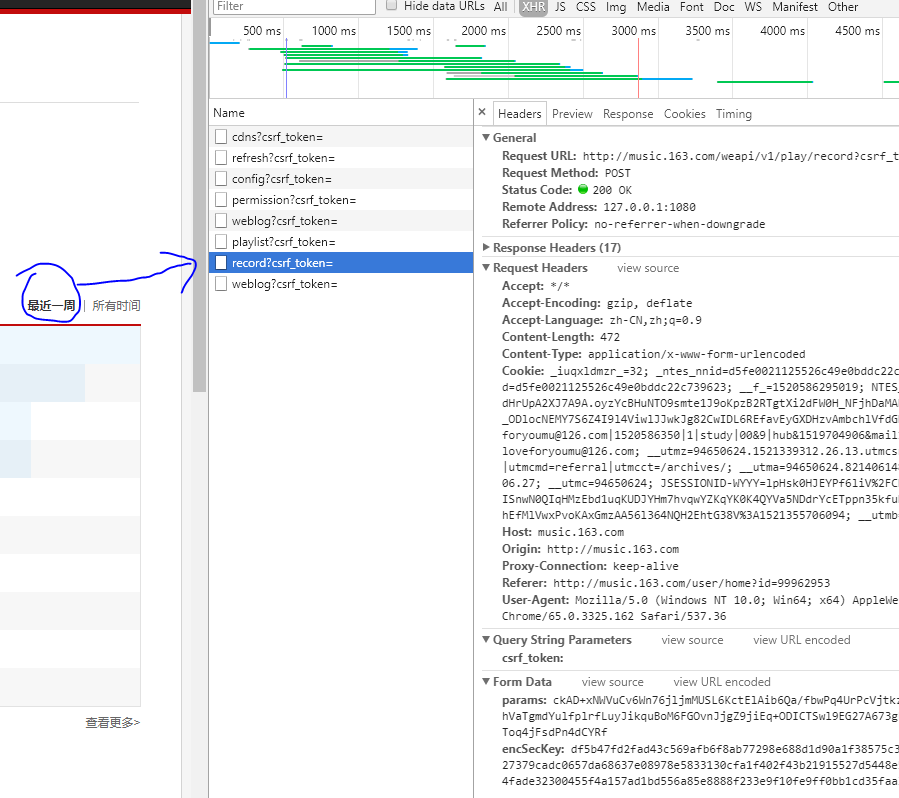
所有时间: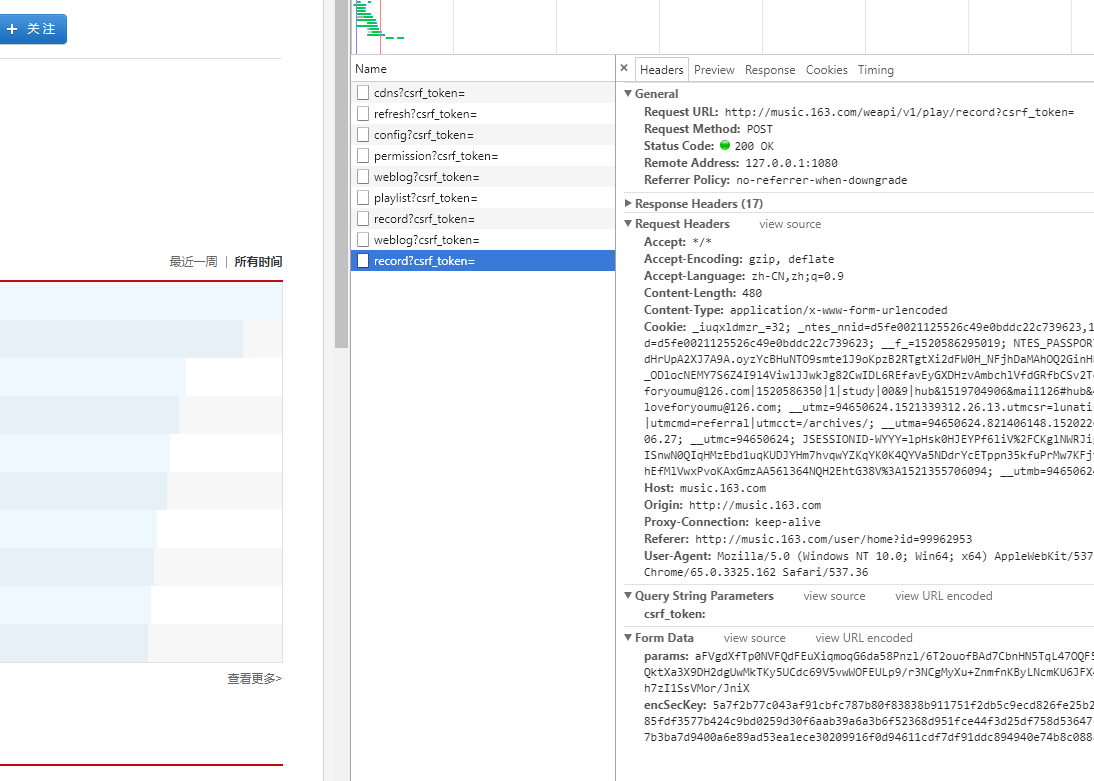
所有时间: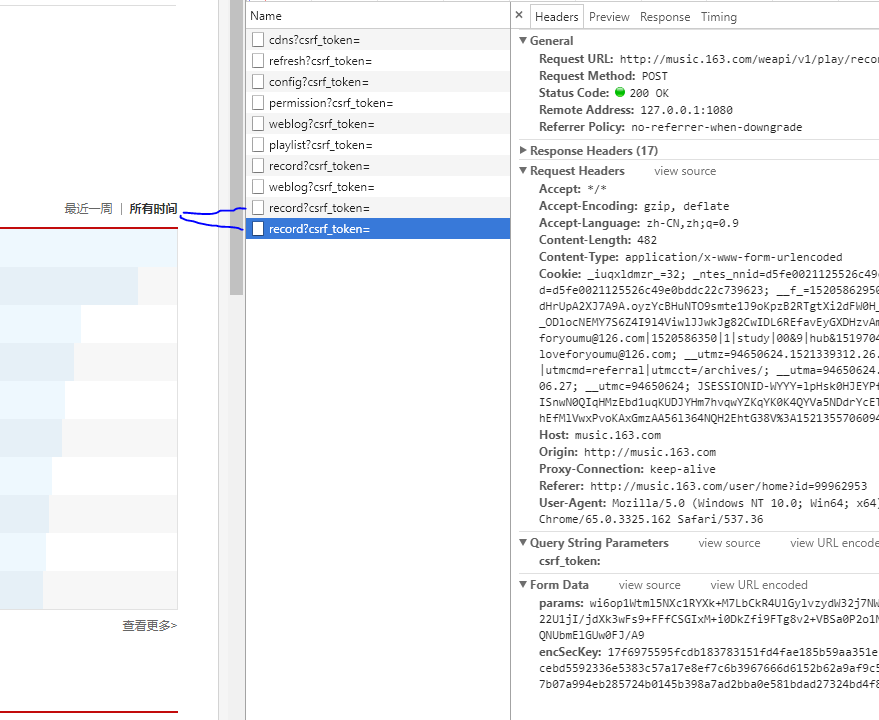
点击了“所有时间”两次,知道他是POST,还有From data。但是相同的From data不一样。我纠结了很久,因为一旦弄清楚Fromdata之后其实就直接用requests即可,但是后来发现他是加密的,心里是一万只草泥马。
所以马上转换思路,用selenium+chrome。也就是模拟浏览器在浏览该页面,然后等我们需要的动态数据加载完以后获取网页源代码,然后提取信息,至此思路解决。
用户的身份确定不是用户名,而是ID唯一确认,因为用户名会改变。
功能实现
爬取听歌排行
基于此,网易云虽然推出了“我喜欢的音乐”,但是喜欢是喜欢,真正喜欢的还是那些我们听的多的。
因为听的越多,越证明我喜欢这首音乐,也切合人的一种听歌状态。
爬取听歌排行代码
def Work_Mian(id, state=1 , id1=1):
chrome_options = webdriver.ChromeOptions()
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument("--window-size=1280,800")
chrome_options.binary_location ="H:\Program Files (x86)
\Chrome\Application\chrome.exe"
# 声明浏览器
a = webdriver.Chrome(chrome_options=chrome_options)
# 爬取地址
url = 'http://music.163.com/#/user/songs/rank?id='
url = url+id
try:
a.get(url)
# 从window转到ifram
a.switch_to.frame('g_iframe')
# 显式等待声明
wait = ui.WebDriverWait(a, 15)
# 等待 a.find_element_by_class_name('g-bd') 记载
if wait.until(lambda a: a.find_element_by_class_name('g-bd')):
# 判断是否有"所有时间"按钮
if a.find_element_by_xpath('//*[@id="songsall"]'):
# 点击所有时间按钮,页面的ajax同步所有时间的结果
a.find_element_by_xpath('//*[@id="songsall"]').click()
# 强制等待 让界面刷新等待数据出现
time.sleep(0.2)
# 同上
if wait.until(lambda a: a.find_element_by_class_name('g-bd')):
# print(type(a.page_source))
# print(a.page_source)
# 声明正则表达式
pattern = re.compile('<b title=".*?">(.*?)</b>.*?hidefo
cus="true">(.*?)</a>.*?style="width:(.*?);"', re.S)
gorp = re.findall(pattern, a.page_source)
# 将读取到的数据存入文本文档
for i in gorp:
f = open("song/"+id+'.txt', 'a+', encoding='utf-8')
f.write(i[0]+':'+i[1].replace('\xa0', ' ')+' '+i[2]+'\n')
f.close()
print('存取成功!')
a.quit()
if state == 1:
main()
else:
Net_Compare.compare(id, id1)
except NoSuchElementException:
if state == 1:
print('ID输入错误,请重新输入!')
a.close()
input_id()
if state == 2:
print(str(id)+'该用户数据被设为隐私,不可爬取')
main()
headless是无头浏览器也就是不要浏览器界面,如果有同学需要观看selenium是怎么操作的可以在:
a = webdriver.Chrome('xxxx')
# xxx改成你下载chrome驱动的位置,一般把下载好的放到chrome的安装目录中。
整体而言就是模拟浏览器的操作,这样就避免了ajax的问题,收集到的数据也存入到了文本文档中,方便查阅,当然也可以放到数据库中。
数据匹配对比
网易云最好的一个功能就是他的评论,让一群人找到了归属感。”看看我喜欢的音乐有多少人喜欢,又有多少故事。”,但是现如今的网易云虽然也有好友系统,但是太过于简单。很多人都想要志同道合的人,希望遇到大家喜欢听的音乐一样—>圈子。
相比较自己,我也希望能有这样一个功能。
没有?那我自己写~
匹配对比代码
def ztt(id , id1):
try:
ztt = codecs.open('song/'+id+'.txt', 'r', encoding='UTF-8')
except IOError:
print(str(id)+'正在存取该用户数据,请稍后')
NetMusicDome.Work_Mian(id, 2, id1)
ztt = codecs.open('song/' + id + '.txt', 'r', encoding='UTF-8')
else:
content = ztt.readlines()
for i in range(len(content)):
content[i] = content[i][:-8]
return content
def compare(id1, id2):
print('正在对比,请稍后.....')
one = ztt(id1, id2)
two = ztt(id2, id1)
sum = 0
try:
for z in one:
for y in two:
if z == y:
sum = sum + 1
print(z)
except TypeError:
a = 0
else:
print('你们之间的歌曲匹配度是:' + str(sum) + '%')
很简单的遍历查询,还有就是注意用’r’,先做文件查询,如果没有在爬取一下。
整体代码
NetMusicDome.py
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
import re
import Net_Compare
from selenium.common.exceptions import NoSuchElementException
"""
思路:因为网易云是ajax,所以单纯采用requests和BeautifulSoup是很难实现的,
有些网站可以实现,但是网易云的js的请求是post,并且date是动态变化加密的。
所以这里我们引入selenium库来模拟浏览器行为获取网页。
1,先用显式浏览器在测试代码
2,显式完毕之后调用head less来进行测试
3,放置服务器进行设置
"""
def Work_Mian(id, state=1 , id1=1):
chrome_options = webdriver.ChromeOptions()
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument("--window-size=1280,800")
chrome_options.binary_location ="H:\Program Files (x86)\
Chrome\Application\chrome.exe"
# 声明浏览器
a = webdriver.Chrome(chrome_options=chrome_options)
# 爬取地址
url = 'http://music.163.com/#/user/songs/rank?id='
url = url+id
try:
a.get(url)
# 从window转到ifram
a.switch_to.frame('g_iframe')
# 显式等待声明
wait = ui.WebDriverWait(a, 15)
# 等待 a.find_element_by_class_name('g-bd') 记载
if wait.until(lambda a: a.find_element_by_class_name('g-bd')):
# 判断是否有"所有时间"按钮
if a.find_element_by_xpath('//*[@id="songsall"]'):
# 点击所有时间按钮,页面的ajax同步所有时间的结果
a.find_element_by_xpath('//*[@id="songsall"]').click()
# 强制等待 让界面刷新等待数据出现
time.sleep(0.2)
# 同上
if wait.until(lambda a: a.find_element_by_class_name('g-bd')):
# print(type(a.page_source))
# print(a.page_source)
# 声明正则表达式
pattern = re.compile('<b title=".*?">(.*?)</b>.*?
hidefocus="true">(.*?)</a>.*?style="width:
(.*?);"', re.S)
gorp = re.findall(pattern, a.page_source)
# 将读取到的数据存入文本文档
for i in gorp:
f = open("song/"+id+'.txt', 'a+', encoding='utf-8')
f.write(i[0]+':'+i[1].replace('\xa0', ' ')+' '+i[2]+'\n')
f.close()
print('存取成功!')
a.quit()
if state == 1:
main()
else:
Net_Compare.compare(id, id1)
except NoSuchElementException:
if state == 1:
print('ID输入错误,请重新输入!')
a.close()
input_id()
if state == 2:
print(str(id)+'该用户数据被设为隐私,不可爬取')
main()
def input_id():
print('请输入你要爬取的用户ID:')
id = input()
Work_Mian(id)
main()
def Compare():
print('请输入你要对比的第一个用户ID:')
one = input()
print('请输入你要对比的第二个用户ID:')
two = input()
Net_Compare.compare(one, two)
main()
def main():
print('请输入数字选择你要的功能:1,存入数据 2,信息匹配 3,退出')
a = input()
if a == str(1):
input_id()
if a == str(2):
Compare()
if a == str(3):
print('beybey!')
exit()
if a != str(2) and a !=str(1) and a!=str(3):
print('输入错误,请重新输入!')
main()
if __name__ == '__main__':
main()
Net_Compare.py
# 无聊写一个对比歌曲重合度的一个小Dome
import codecs
import NetMusicDome
def ztt(id , id1):
try:
ztt = codecs.open('song/'+id+'.txt', 'r', encoding='UTF-8')
except IOError:
print(str(id)+'正在存取该用户数据,请稍后')
NetMusicDome.Work_Mian(id, 2, id1)
ztt = codecs.open('song/' + id + '.txt', 'r', encoding='UTF-8')
else:
content = ztt.readlines()
for i in range(len(content)):
content[i] = content[i][:-8]
return content
def compare(id1, id2):
print('正在对比,请稍后.....')
one = ztt(id1, id2)
two = ztt(id2, id1)
sum = 0
try:
for z in one:
for y in two:
if z == y:
sum = sum + 1
print(z)
except TypeError:
a = 0
else:
print('你们之间的歌曲匹配度是:' + str(sum) + '%')
Output
音乐信息存取
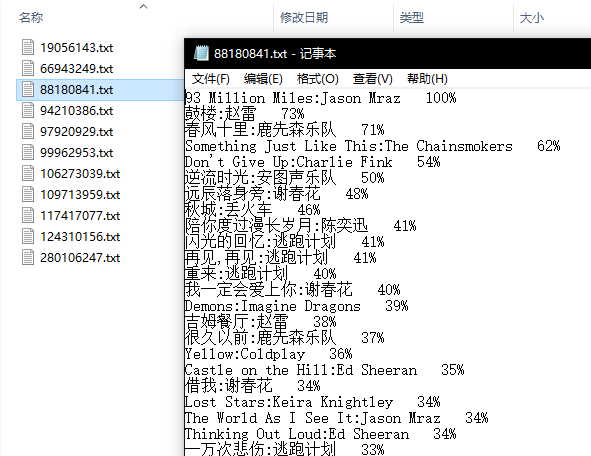
匹配对比
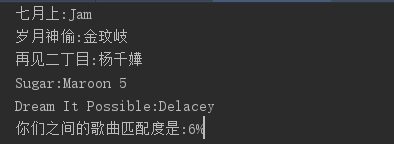
Dome展示


一些想法
想实现这个网易云很大一部分因为自己喜欢,第二个部分是因为在和同学企划一个小项目,不管从哪个方向来说,都值得去做。
奈何自己没有三头六臂,也不是十全十美,但是现在总希望事情能够做的更好,仅此而已~
Down
关于爬虫对于我来说还有很多,下一步就是自己最想爬的https://www.tumblr.com/,好好开始。
嗯。