
Demo
终于开始学习Python的爬虫,刚刚入门。但是现在对于我来说一般的静态网站爬下来没有问题了。
所以来说说这几天三个小Dome的思路。
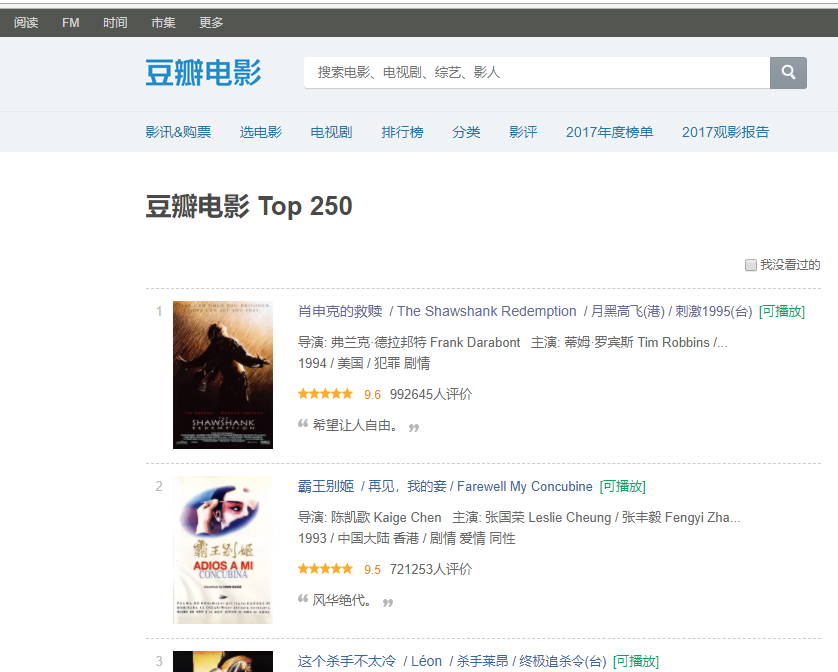
豆瓣电影的TOP250
第一个小Dome是“豆瓣电影的TOP250”的爬取,因为喜欢看电影,所以选了豆瓣来爬。用到的也是最基础的requests库以及re,辅助于正则表达式。最开始对正则还是有所压力的,但是接触之后才发现其实简单的爬取所需要的正则挺简单。
首先
我们需要一口进入到豆瓣电影,一般而言就是TOP250的首页:https://movie.douban.com/top250?start=0,发现start后的值其实就是翻转的页数,也就是说当“start=25”跳转到下一页。为什么是25呢?因一页有25部电影啊~然后我通过观察发现每一页的布局整体而言是相同的,也就是说只要我们能够爬取一页我们需要的信息,那么通过遍历我们也就获得了所有需要的电影信息。
我们需要什么?
通过chrome(或者别的浏览器)的检查,一部电影的信息全部在一个li标签下,那么知道这些信息之后我们就可以通过正则表达式来筛选我们需要的信息。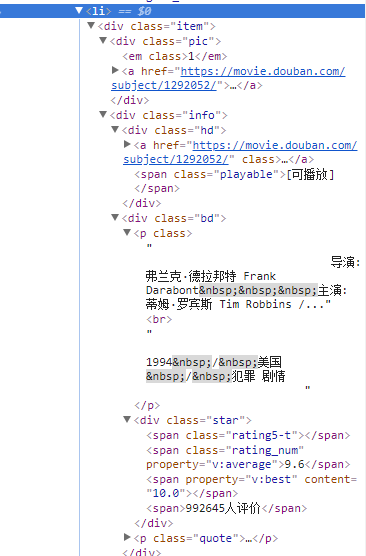
def get_one_page(url):#页数选择
try:
response=requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<img.*?src="(.*?)".*?title">(.*?)\
</span>.*?"">(.*?)<.p>.*?age">(.*?)</span>.*?\
<span>(.*?)</span>', re.S)
items = re.findall(pattern, html)
for item in items:
print(item)
def main(url):#主方法
html = get_one_page(url)
parse_one_page(html)
# print(url)
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start='
url1='&filter='
for i in range(0, 225, 25):
url3 = url+str(i)+url1
main(url3)
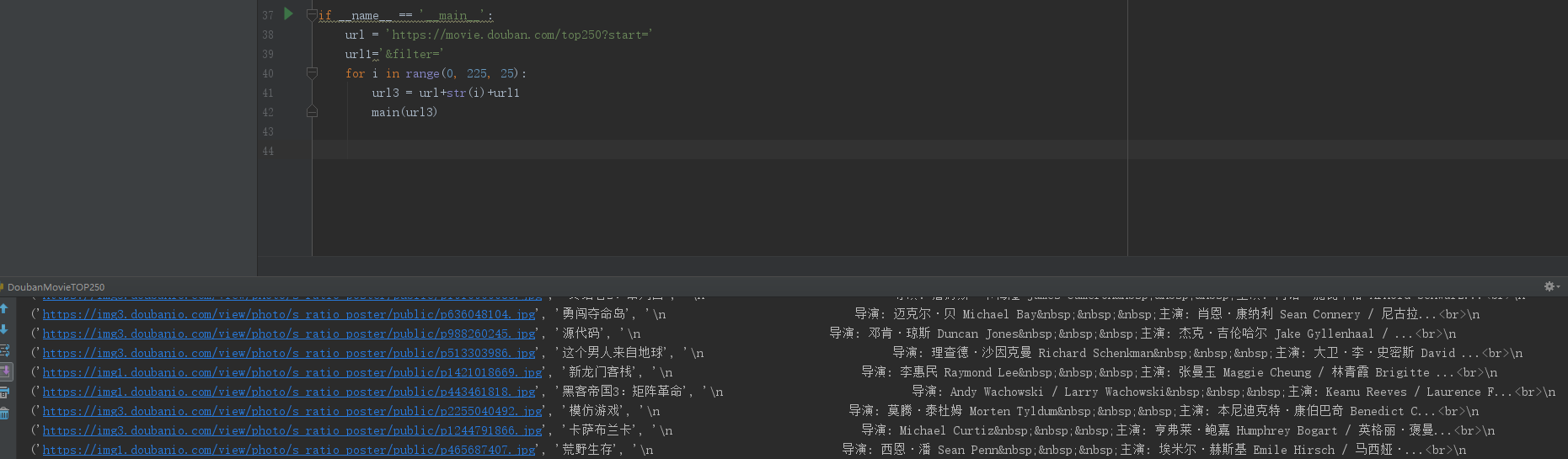
‘response=requests.get(url)’,requests.get(url)会解码服务器的内容,’response.text’将网站的源码解析出来。’re.compile()’的两个参数分别是正则表达式,和跨行。没有re.S是不能进行跨行搜索的。然后在将传到’re.findall()’查找所有正则表达式里的信息,然后进行输出,我们得到的’items = re.findall(pattern, html)’是一个结果集,所以需要遍历。
结果
爬取猫眼电影TOP100
猫眼电大体上与豆瓣电影的方法相同,只不过我试着把数据存放在数据库中。
数据库.test
def get_page(url):##将爬取到的数据存入自己的数据库
html = requests.get(url, headers=headers)
# Mysql = Set_Mysql()
# Mysql.add(Mysql.cursor,data)
connect = pymysql.Connect(
host='xxx.xxx.xxx.xxx',
port=3306,
user='root',
passwd='root',
db='Python',
charset='utf8'
)
cursor = connect.cursor()
for item in requstst_paly(html.text):
name = item.get('name')
foot = item.get('foot')
time = item.get('time')
mark = item.get('mark')
img = item.get('img')
data = (name, foot, time, mark, img)
sql = "INSERT INTO CatEyeMovie (MovieName, Protagonist
, ReleasedTime
,Score,Poster) VALUES ( '%s', '%s', '%s','%s','%s')"
cursor.execute(sql % data)
print(mark)
connect.commit()
def requstst_paly(html):##用正则表达式提取信息,使用“yield”创造字典
pattern = re.compile(
'<img data-src="(.*?)@.*?".*?"name".*?">/
(.*?)</a>.*?star">(.*?)</p>.*?time">/
(.*?)</p>.*?ger">(\d.).*?">(\d)</i>', re.S)
items = re.findall(pattern, html)
for movie in items:
yield {
'name': movie[1],
'foot': movie[2].strip()[3:],
'time': movie[3].strip()[5:],
'mark': movie[4] + movie[5],
'img': movie[0]
}
我们创造一个构造器,将爬取到的信息存到字典。
for movie in items:
yield {
'name': movie[1],
'foot': movie[2].strip()[3:],
'time': movie[3].strip()[5:],
'mark': movie[4] + movie[5],
'img': movie[0]
}
因为对Python还是不很熟悉,原本想写个类来封装数据库链接,但是后来发现对于我来说不是很好实现,索性就加入到方法中了。需要注意的是在加入’import pymysql.cursors’,还有在创建表的时候需要注意字符个数,不然就会报错,不然就很难受~
结果

爬取3DM游戏排行榜迅雷下载地址
室友说:诶,你最近在学爬虫?你帮我把游戏的下载地址爬取下来吧,不然每次都要点很多网站。
有练手的机会当然欣然答应。
分析
在找寻游戏下载过程中发现,一款在3DM中的游戏,真实的下载地址是需要点击三个页面才能找到的。这很繁琐,而且3DM和游侠下载界面也不够友好。
这让我们很头疼~
但是这次的难度在于我刚接手的时候对“onclick”,因为事件告诉我们他是动态加载的,其次不能马上通过return一个完整的静态网页,因为事件还未加载。而且也打算用更简单的BeautifulSoup库来完成。
一
通过http://dl.3dmgame.com/pc/click_desc/我们得到第一张图的结果,分析页面列表的游戏主页面的url,然后加载到游戏主页面得到游戏的相关信息,因为很多游戏都不相同,我也懒的做分情况处理,所以就只是获取了游戏名称。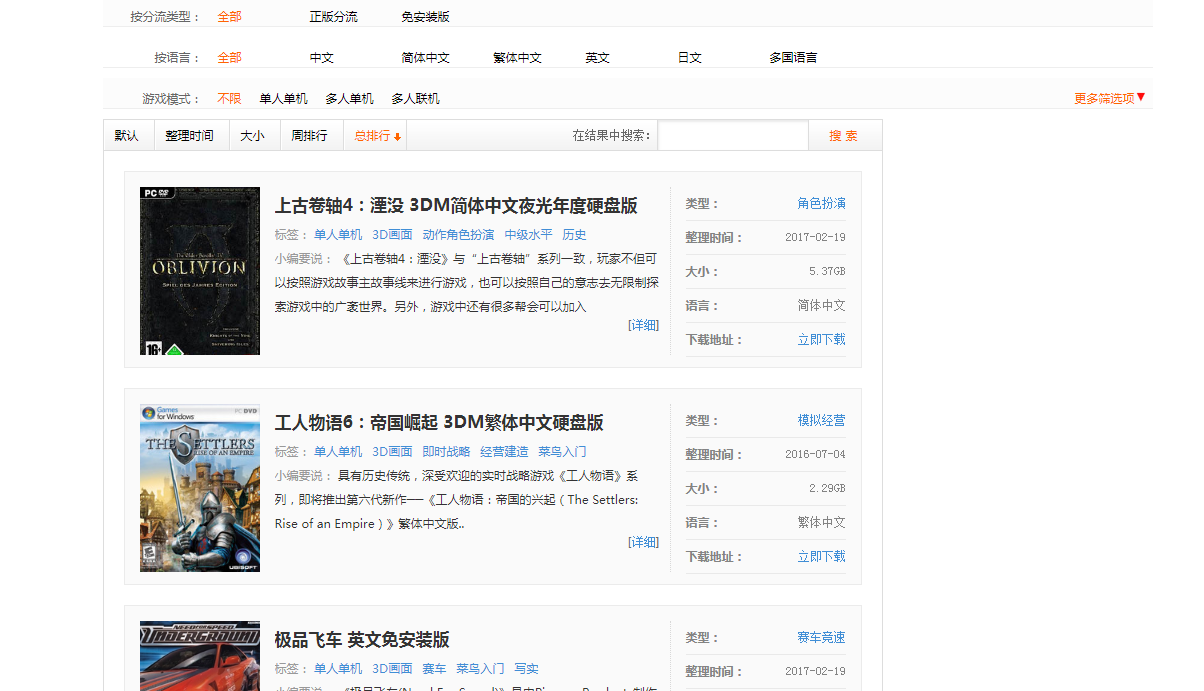
二
在得到游戏的主页面并且得到游戏名称,那么我们就要找到游戏的下载跳转。但是前面我说过,下载页面的地址是通过‘onclick’来动态加载的,直接获取是获取不到的,那么我们能不能用浏览器来模拟点击然后得到跳转地址呢?
答案是可以,这里需要一个selenium库来模拟浏览器的点击然后在获得下载地址的跳转。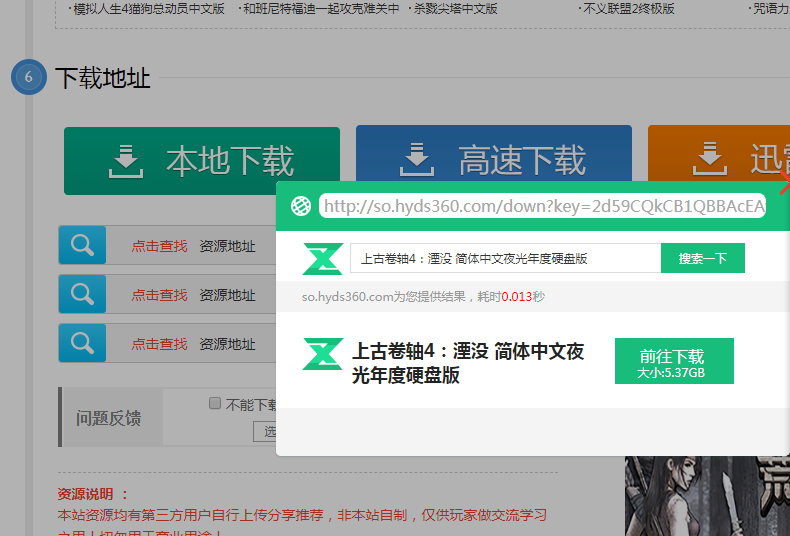
onclick中的showXiazai()方法来实现下载页面跳转。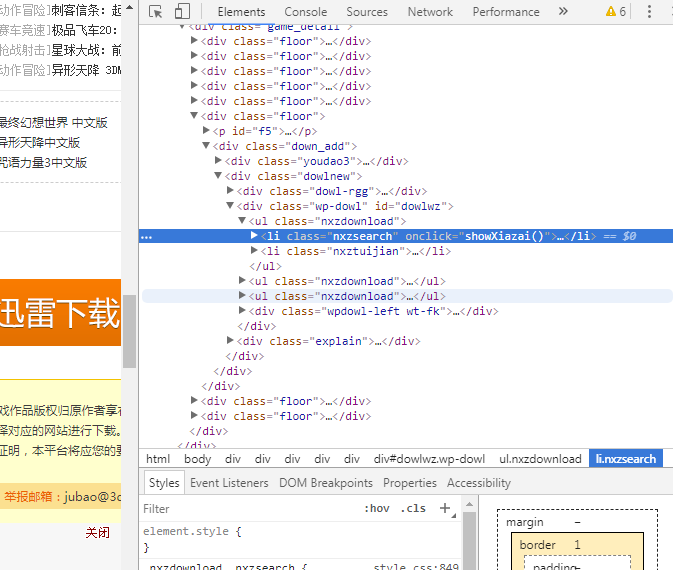
三
得到了下载后的地址就可以为所欲为了。在该页面中有三个下载选项分别是:极速下载,迅雷链接下载,网盘下载。因为迅雷对下载的友好程度还是比较高,而且很多游戏不一定都有极速下载以及网盘下载,所以选用迅雷的下载地址作为return。
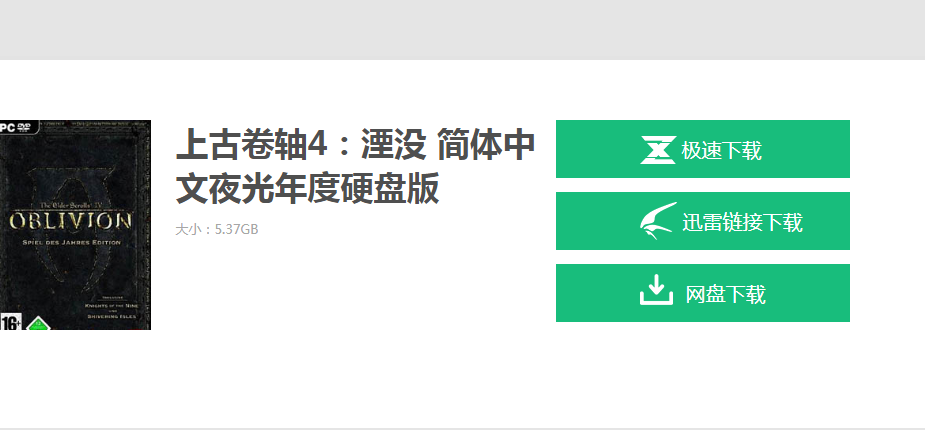
代码
def fater_url(url):
# 游戏页面链接获取
rosepse = requests.get(url)
soup = BeautifulSoup(rosepse.text,'lxml')
href = soup.select('div.text > h2 > a')
for i in href:
son_url(i.get('href'))
# 进入单个游戏界面
def son_url(url):
son_rosepse = requests.get(url)
son_rosepse.encoding = 'utf-8'
#print(son_rosepse.text)
#time.sleep(10)
son_suop = BeautifulSoup(son_rosepse.text, 'lxml')
game_name = son_suop.select('div.game_wrap > h1')
down_game = son_suop.select('#xzhzdownurl')# 找到下载页面,进行分析
hard = 'http://so.hyds360.com'
for j in down_game:
# 获取游戏名
print(game_name[0].text)
f = open('game.txt', 'a+', encoding='utf-8')
f.write(game_name[0].text+'\n')
f.close()
#加入判断,某些页面的链接会失去“http://so.hyds360.com”的头,手动加上。
if 'http' in j.get('value'):
grandson_url(j.get('value'))# 分析下载页面
else:
new_url = hard+j.get('value')
grandson_url(new_url)
def grandson_url(html):
if len(html):
grandson_rosepse = requests.get(html)
grandson_rosepse.encoding = 'utf-8'
grandson_suop = BeautifulSoup(grandson_rosepse.text, 'lxml')
# 获取次级下载页面
grandson_url = grandson_suop.select('a.result_down')
if grandson_url != None:
str = grandson_url[0]['href']
down_rosepse = requests.get(str)
down_rosepse.encoding = 'utf-8'
grandson_suop = BeautifulSoup(down_rosepse.text, 'lxml')
down = grandson_suop.select('body >
div.yxhz_n1_container > div.n1_content >
# 获取真实下载页面
a.gameDown.down_xl')
print()
f = open('game.txt', 'a+', encoding='utf-8')
if down.__len__() == 0:
f.write('没有迅雷下载地址!' + '\n')
else:
f.write(down[0]['href'] + '\n')
f.close()
在实际操作中会解决和优化很多问题,比如“响应事件”的问题。selenium调用chrome进行模拟点击的时候虽然可以,但是预期效果一直未达到,在仔细的分析网页源代码后发现跳转的下载地址在最后,而并非页面显示的对应位置,那么也就无需selenium。
本次也将结果写入了文本文档,方便查询。
结果

杂碎
总体而言这三个小Dome都较为简单,但是如果作为入门的练手项目也是足够了。中间遇到了许多问题,都一点点的解决,不论是直接还是幽暗曲折的达到结果总归是好的。但是我难免还是想更加优化,本事不够,修炼不够。还是需要做很多很多。
还有重要一点要学会开始看官方文档,这样也能够更加透彻的明白作者的心血和巧妙的构思。
github
代码我都上传到github上,以备能有幸被其他初学者学习,也能回头对自己代码进行分析。
Github: https://github.com/LunaticTian/Python-reptilian-Test
下一步计划
完成网易云音乐的用户喜爱音乐的爬寻~